本計劃的基礎工作(以下稱「原計劃」)是由何秀煌教授主持的「人類認知跨科比較研究室」於一九九二至一九九八年間進行的。計劃完成時,研究人員把研究所得,包括基本統計數表、和各種跨地區、跨年代的比較數表等材料,印成一套共十四本的 研究報告,作為研究的總結。該份報告只印了三份,其中一份曾交予中文大學圖書館庋藏。後來,由於經費理由,研究室的工作沒有繼續,而字頻計劃報告亦未有相應推廣。
到了二00一年初,由於何教授行將榮休,「人文電算與人文方法研究室」同人乃向何教授提出把有關研究材料以新一代的資訊技術重組,和於網絡上發表的建議。建議得到何教授的首肯和全力支持,於此謹代表廣大的用者向何教授致以謝意。
關於漢字的頻率統計,大陸和台灣都曾多次進行,並都取得了不菲成果,都為各地基礎教育作出了一定的貢獻。至於香港,據查證所得,只有一項針對初中學生的詞匯和常用字統計(見蕭炳基等主編:《香港初中學生中文詞匯研究》,香港教育署出版,1986),因此,是次計劃的推行﹐其難得固不待言。不過,更為難得的,是這次的研究計劃提出了「跨地區」和「跨年代」的理念,為字頻研究開闢了新的領域。「人文電算與人文方法研究室」接手這份工作,亦因為覺得這些理念用於字頻研究上,將有極大的發展潛力。是以,在重組材料和鋪排上網的過程中,除了克服各種電算層面的困難外﹐最重要的工作就是設法把「跨地區」、「跨年代」的理念充分予以表達。

關於本網頁的使用細則,可資交代的有以下各點:
-
語料庫的構成:
本網頁收納的現代漢語語料可按地區和年代予以識別。所謂地區,即指香港、大陸和台灣三者,至於年代,則選取了上一世紀的六十年代(1960-1969)和八、九十年代(1980-1993)這兩個段落。時、地兩個因素交疊相乘,便有共六個語料單元。每一語料單元的內容就文體而言,大致可分為抒情、敘事和評論三種;就篇章而言,則分為數百個長短不一的檔案。每一語料單元的字數約在 660,000 字左右。六個語料單元合起來,總共字數為 3,970,514 字。如欲了解詳情,如所選用的語料的篇目等,可循「語料一覽」一超連結查詢。
-
數表的類別:
本網頁提供的有關現代漢語常用字頻率的統計數表共分三種,用者可於網頁左欄以鼠標點鍵查取。三種數表分別是:
- 基本字頻統計數表:這一種數表的功用是把某一語料單元中所含的所有漢字的基本字頻資料列明。所列的資訊項目包括有本字(即單字)、序號、所屬部首、筆劃、頻次、頻率、累積頻次、累積頻率、見檔次和見檔率等,其中本字、序號和頻次三者為原計劃所有(名稱略有不同),其餘則由本網頁新訂。用者可於左欄相關部分的「菜單」中選擇所需地區和年代,然後按鍵查取。
- 跨地區比較數表:這一種數表的功用是把同一年代三個地區的用字的字頻加以比較。查詢時,用者首先要選定一個年代,其次又要於三個地區中選一個作為基準地區,然後按鍵查取。這一種比較數表所列出的資訊項目包括基準地區於有關年代中所使用的所有單字、序號、頻次和頻率;在二個比較地區的欄位下,所列舉者除上開各項外,還增加了相對於基準地區的跨地區頻差一項(解釋詳見下節)。至於年代和基準地區,亦可於左欄相關部分的「菜單」中選擇。
- 跨年代比較數表:這一種數表的功用是把同一地區於二個不同年代中用字的頻率加以比較,並予表列。查詢時,用者得先選定一個地區,然後按鍵查取。列表時﹐我們把選擇地區於二個年代的所有用字排在正中的一欄,然後把這些字於六十年代和八、九十年代的字頻資料分列左、右兩側,以作比較。數表除提供各種有關的基本字頻數據外,還分別列出逆時頻差(左邊)和順時頻差(右邊)兩個項目(解釋詳見下節)。
-
數表的排序:
在原計劃的統計報告中,上述三種數表的排序原則,主要以各字的頻次為準,如遇頻次相同,則參考一般字典中各字的出現先後。在本網頁中,由於材料經過電算重組,排序的基本原則,乃有稍作修改的需要:在按頻次排列時,如遇頻次相同,則按各字於康熙字典的部首表中的先後排列;如部首亦相同,則按各字筆畫的多寡排列;如筆畫亦相同,則按各字Big5內碼碼位先後排列。
除了以頻次為主的排序方式外,本網頁在原計劃統計材料的基礎上,增加了幾種另類的排序格式,對上述三種數表的內容作出了補充或加強。現把這些另類的排序格式分列如下:
- 見檔率:「頻率」的計算,是以某一單字於某一語料單元中出現的頻次除以該單元的總字數,再換成百分比而構成。「見檔率」的計算,則以某一首字於某一語料單元中的「見檔次」(即含有該首字的檔案的數目)除以該語料單元的總檔數,再換成百分比而得出。在一般情況下,見檔率的高低雖然都與字頻的高低成正比,但由於計算方式的不同,二者所反映的意義卻稍有差別。例如在「六十年代香港」這個單元中,「溴」和「憾」兩字的頻次都是 "30"﹐故其頻率亦同為 0.004531%。然而,由於「溴」的見檔次為 "1", 而「憾」的見檔次則高達 "29", 故後者的見檔率 (6.07%) 亦遠較前者的見檔率 (0.21%)為高。因此,在見檔率的考慮下,我們可說就學習的需要而言,「憾」字比「溴」字重要得多。有見及此,本網頁的「基本字頻統計數表」除了提供標準的字頻排序格式外,也支援了以「見檔率」排序的格式。
- 跨地區頻差:「頻差」是本網頁提出的另一個重要的運作概念。頻差嚴格而言,指的是「頻率差率」,也即反映任意兩個需要比較的頻率之間的相對增減程度的百分比。頻差計算的目的,就是把原計劃「跨地區」和「跨年代」的理論特點充分地予以表述。跨地區頻差的計算,必需先認定某一地區作為參考基準(即上面所謂「基準地區」),然後以其餘兩地區的材料與之比較。設(某一字於)基準地區的頻率為(R), 而(其於)比較地區的頻率為(C), 則有關的跨地區頻差就是:((C-R)/R)*100%。由於基準地區和比較地區可以不同方式組合,本網頁計算跨地區頻差時,一律以基準地區居先,和以比較地區居次的格式命名,因而可得出港陸、港台、陸港、陸台、台港和台陸等共六種跨地區頻差,其計算一律有如上式。本網頁列出「跨地區比較數表」時,除了提供以基準地區序號(等同頻次)為排序原則的格式外,還容許用者以兩種(相對於基準地區的)跨地區頻差為排序原則去重組數表。
- 跨年代頻差:把頻差概念應用到同一地區兩個年代用字的頻率的比較之上,便構成跨年代頻差的考慮。在跨年代頻差的計算中,如把較早年代訂為參考的基準,而順著看較後年代的變遷,由此而計算出來的頻差可稱為「順時頻差」;如以較後年代為基準而逆時地溯求既往年代的字頻狀況,則可稱之為「逆時頻差」。無論順逆,計算方式同樣可以((C-R)/R)*100%一公式概括之(此中, R 和 C 分別指基準年代和比較年代的有關頻率)。同樣地,在列出「跨年代比較數表」時﹐除了以基準年代用字的序號為排列原則外,用者亦可選擇以順時頻差或逆時頻差作為排序準則。
-
個別單字統計資料的數表顯示:
本網頁整個語料庫(共六個單元)共包含了 6507 個單字。為了對每一單字提供一概括性的總結,用者可透過不同途徑按鍵顯示某一單字的專頁。提取單字專頁的途徑有多種:包括
- 各統計數表中每一行列出單字時即自動建立了通往單字專頁的超連結。
- 在網頁頂欄的黃色方格內,用者可直接輸入某一單字,按鍵後即可直達該字的專頁。若本語料庫六個單元都未包含該字,則仍提供相關的超連結,以便用者。
- 網頁頂欄黃色方格內另有一「部首檢索」的超連結,用者按鍵即可通往「部首總表」,該表按康熙字典部首次序排列,用者可循此途徑通往不同部首的單字。
- 除以上三個途徑外,本網頁更為本計劃Big5中文編碼以外的造字另設一「造字總表」﹐讀者循此途徑可通往有關造字的專頁。
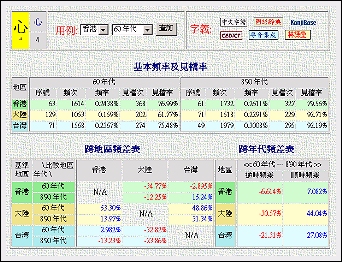 一單字的專頁首先提供了該單字的字型、部居、畫數、和通往本研究室或其他海外團體開發的,有關該字的語義和語音資訊的超連結。然後,便以表列的方式,排出「基本頻率及見檔率」、「跨地區頻差表」和「跨時代頻差表」等三個數表,目的是列明該單字的主要統計資料和各種頻差數值(見右圖)。除此以外,亦於數表的右側列出由這些基本數據用程式隨機地自動繪成的一些圖表(詳見下一節),和提供了該字於整個語料庫六個單元中的所有實際用例等訊息(詳情見再下一節)。
一單字的專頁首先提供了該單字的字型、部居、畫數、和通往本研究室或其他海外團體開發的,有關該字的語義和語音資訊的超連結。然後,便以表列的方式,排出「基本頻率及見檔率」、「跨地區頻差表」和「跨時代頻差表」等三個數表,目的是列明該單字的主要統計資料和各種頻差數值(見右圖)。除此以外,亦於數表的右側列出由這些基本數據用程式隨機地自動繪成的一些圖表(詳見下一節),和提供了該字於整個語料庫六個單元中的所有實際用例等訊息(詳情見再下一節)。
-
個別單字統計資料的圖表顯示:
為求對各單字的統計資料有一更直接和明晰的掌握,本網頁更把一些重要統計資料以圖表的方式顯示。用者如以任何方式呼叫某一單字的專頁時,有關該單字的統計圖表即會於網頁右側欄位自動出現。到目前為止,我們供的圖表共有兩種(三個),即「頻次圖」和「見檔率圖」二者。上述兩種圖表的基本設計,就是把本語料庫六個單元的相關資料以視像格式同時展示,以便用者同時掌握其中的「跨年代」和「跨地區」等複雜關係。
- 頻次圖:由於六個語料單元的字數大約都在660,000左右,我們選撢了直接以頻次作為圖像顯示的依據。由於頻次的數值最小是 "0", 而最高可達 "30,617" 之譜,為了於有限空間中把如此大範圍的數值表達,較有效的方法就是以「對數」(logarithm)計算。
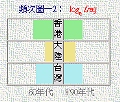 為了較清楚地顯示高頻次和低頻次的數值,我們分表用了以 log10 和 loge 為基數的 兩種算法,讓用者隨機參考。頻次圖的一般用法是:橫看可比較各地區的跨年代頻次(順時和逆時頻差);垂直看則可靈活地讀取各地區的頻次,並因此隨機地掌握任何兩地、甚至三地之間的跨地區頻差。
例如,在察看 皆、焉、其、乎、之、矣、莫、也、云、未、及、遂、若、則、乃、亦、兮、彼、此、非、孰、倘 等文言虛詞時(特別是「皆」、「焉」、「矣」等較純粹的古文元素),我們立刻可指出其「頻次圖」大致上都呈「工字形」(見右圖:以「矣」字為例),這表示大陸地區文言虛詞用得較港台為小;此外「工字形」的「腰身」一般而言,右邊比較粗,這表示大陸地區近年來用這些字已較六十年代為多。其中有沒有政治、社會和文化上的意義,用者可自行揣度!
為了較清楚地顯示高頻次和低頻次的數值,我們分表用了以 log10 和 loge 為基數的 兩種算法,讓用者隨機參考。頻次圖的一般用法是:橫看可比較各地區的跨年代頻次(順時和逆時頻差);垂直看則可靈活地讀取各地區的頻次,並因此隨機地掌握任何兩地、甚至三地之間的跨地區頻差。
例如,在察看 皆、焉、其、乎、之、矣、莫、也、云、未、及、遂、若、則、乃、亦、兮、彼、此、非、孰、倘 等文言虛詞時(特別是「皆」、「焉」、「矣」等較純粹的古文元素),我們立刻可指出其「頻次圖」大致上都呈「工字形」(見右圖:以「矣」字為例),這表示大陸地區文言虛詞用得較港台為小;此外「工字形」的「腰身」一般而言,右邊比較粗,這表示大陸地區近年來用這些字已較六十年代為多。其中有沒有政治、社會和文化上的意義,用者可自行揣度!
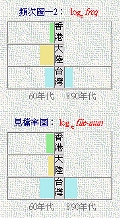 見檔率圖:對大多數單字而言,「見檔率圖」與「頻次圖」的形態是很類近的。但正如前面提及,頻率和見檔率的高低雖然一般都成正比,但由於計算的方法不同,則對某些單字而言,其頻率和見檔率計算的結果卻會出現不盡相符或不對稱的關係。這些特殊的情況出現時,「見檔率圖」與「頻次圖」便會表現出不同的空間形態,用者一看之下會很容易察覺。
例如 舜、鑫、舅、磯、砦、韶 等字(見右圖:以「韶」字為例,圖上方的圖表是「韶」字的頻次圖,而下方的則為「韶」字的見檔率圖)。這種分歧的出現,最主要的理由是某一單字的使用過度地集中於語料庫的某一兩篇選材中。因此,在出現上述圖表分歧情況時,有關的單字頻率統計的效力便必須被檢討。至於這一圖表有沒有其他用途,便有待用者自己去發掘了。
見檔率圖:對大多數單字而言,「見檔率圖」與「頻次圖」的形態是很類近的。但正如前面提及,頻率和見檔率的高低雖然一般都成正比,但由於計算的方法不同,則對某些單字而言,其頻率和見檔率計算的結果卻會出現不盡相符或不對稱的關係。這些特殊的情況出現時,「見檔率圖」與「頻次圖」便會表現出不同的空間形態,用者一看之下會很容易察覺。
例如 舜、鑫、舅、磯、砦、韶 等字(見右圖:以「韶」字為例,圖上方的圖表是「韶」字的頻次圖,而下方的則為「韶」字的見檔率圖)。這種分歧的出現,最主要的理由是某一單字的使用過度地集中於語料庫的某一兩篇選材中。因此,在出現上述圖表分歧情況時,有關的單字頻率統計的效力便必須被檢討。至於這一圖表有沒有其他用途,便有待用者自己去發掘了。
從現代大腦科學的觀點看,人類處理數字信息用的是左腦,而處理圖像信息,用的卻是右腦。此中,數字的表達雖然可以很精確,但卻不如圖像顯示那樣容易被全面掌握。用者如能對單字的圖表善加運用,當較能看出一些單憑數表所不易看見的內在關係。
-
單字用例的顯示:

每當用者進入了某一單字的專頁以後,都可於專頁上方「用例」一欄中以鼠標從有關「菜單」中選擇該字於六個語料單元中某一個單元的所有用例。按鍵後,用例將於最右側的欄位內顯示。顯示時,每一用例一般都由九個字組成,有關的單字一律居中排列,單字的前和後都分別配以四個字的前後文(見右圖)。由於在原計劃中所有標點已被刪除,故用例中不含標點。用者看過某一單元之用例後,如欲改看其他單元之用例,可從「菜單」中改選他項。如欲重新察看統計圖表,則可用鼠標於黃色方格單字(首字)下方的黃色小點上按鍵返回圖表欄。
-
內碼及造字:
漢字的內碼至今尚未統一,固所周知。本計劃所涉及的語料庫既然有「跨地區」的特性,則不同地區的語料的內碼如何比較,乃成為一重要問題。關於這一點,原計劃早訂定了一套策略,現特從原計劃的報告卷首的「資料剖析」部分節錄有關說明如下:
- 「字體和字形是兩個要注意的問題。我們的基本原則是字體以繁體字為準。因此,我們將大陸的資料以繁體字輸入,但是,由於一些文章以討論文字為主題,所以一些簡體字會出現在大陸的字頻統計。以繁體字為主的港、台兩地,則按資料原稿的字體輸入;但是,簡體字的推行對港、台兩地的文字媒介存有一定的影響,所以,簡體字也出現在港、台兩地的字頻統計。」
- 「字形的問題比較複雜。我們的基本原則是字形以資料原稿所載為準,但是其中涉及正體、或體、異體和俗體字的關係,所以我們須要略作說明。因為所有資料須要輸入電腦,所以,文書處理軟件的字庫所儲存的字便對此問題產生重大影響。基於我們以資料原稿所載的字形為準,無論是正體、或體、異體或俗體字,只要字庫存有的,我們都會準照輸入。若果是字庫沒有的正體字,我們會輸入其或體或異體字代替,而造字為最後方法。若果是字庫沒有的或體或異體字,我們會輸入其正體、或體或異體字代替,而造字為最後方法。若果是字庫沒有的俗體字,我們會輸入其正體、或體或異體字代替。除了上述兩個情況下我們會造字外,另外一個決定我們是否造字的因素就是字形的常用性。無論那是一個正體、或體、異體或俗體字,只要這個字是常用的,我們就會把它造下來。例如:
 、
、 、
、 、
、 、
、 字等等。最後一個有關字形的問題就是數字。由於我們只輸入中文字,因此所有阿拉伯數字和『○』都被刪除。」
字等等。最後一個有關字形的問題就是數字。由於我們只輸入中文字,因此所有阿拉伯數字和『○』都被刪除。」
至於本網頁的造字問題,為了避免中文內碼的進一部混亂﹐我們一貫了「人文電算與人文方法研究室」的策略,原則上不為用家設立內碼造字檔 (user fonts),而直接用圖型顯示。用者於網頁頂欄黃色方格內可透過「造字」一超連結取得本網頁全部共 103 個造字的總目。
-
其他技術細則:
- 硬件:本網頁於 HP-9000 D-390 伺服器上建立,操作系統為 HP-UX Release 11.00。
- 軟件:本網頁所用的軟件主要有 Perl, PHP, MySQL 等。
- 解像度:由於本網頁結構頗為龐大,且涉及多種數表和圖表,為保證一理想的熒幕顯示,我們建議用者把熒幕的解像度調至 1024*768。如果只有 800*600
的解像度,則起碼要把字型調到"小",才能確保效果。
- 顏色:本網頁的字頻資料跨越三個地區,為方便用者,統一以綠色代表香港,以米黃色代表大陸,和以天藍色代表台灣。所有由運算而得出的頻差數值如果是正數值,則以軍藍色顯示,如屬負數值,則以紅色顯示之。
- 數學運算:由於計算各單字的頻率時所得的數值差別極大,故表達時沒有採用固定小數點方法,而改以四個有效數字 (significant figures)表達。各種頻差的計算結果的相差輻度雖然較窄,但為了精確地比較各個單字經過複雜運算而得的結果,便也用了四個有效數字去表達。至於見檔率的計算,由於運算簡單,而且沒有精確比較的需要,因此只使用了兩個小數點。在計算跨年代頻差時,如遇上「除零」(Divide by zero) 的運算難題,一律以 Perl Script 另作處理並解決之。本語料庫各單字的字頻由 "0", "1" 至數萬不等,其中頻次為 "1" 者為數甚多!而由於 log101 和 loge1 的數值都是 "0",為了使頻次為 "1" 的許多單字於圖表上與 "0" 頻次有視覺上的分別﹐我們在以 logarithm 計算圖表中各種有關數值時,故意把 log101 和 loge1 以一極窄的線段表達;基於同樣道理,在以 logarithm 處理見檔率時,由於有關數值可低至 0.21, 0.24, 0.28 0.31, 0.40…等,其 logarithm 值應為負數,如此便跟本無法製表。因此我們乃得先把所有見檔率按比例全部乘大,然後才以 logarithm 處理之。
- 標准方差:標準方差是最常用的描述數據分佈及波動程度的測量指標,通常用希臘字母 s,或SD來表示。 標準方差的定義是 s=
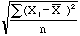 (Xi=每個字的頻率,"X-bar"= 平均值 = 數據總和/數據總個數)。 一個數據的集合的標準方差越大,說明該集合的數據值與平均值的差異越大,數據的波動程度則越大。在分析网頁中的6個語料單元時,若某一語料單元的標準方差越大,說明該單元中字的頻率分佈廣,即有較多的字是分佈得較極端或偏離平均值較遠。此圖表資料可在語料一覽 內找到。有關標準方差,請在這裡查找英文資料或中文資料。
(Xi=每個字的頻率,"X-bar"= 平均值 = 數據總和/數據總個數)。 一個數據的集合的標準方差越大,說明該集合的數據值與平均值的差異越大,數據的波動程度則越大。在分析网頁中的6個語料單元時,若某一語料單元的標準方差越大,說明該單元中字的頻率分佈廣,即有較多的字是分佈得較極端或偏離平均值較遠。此圖表資料可在語料一覽 內找到。有關標準方差,請在這裡查找英文資料或中文資料。
最後我們希望指出,從教育規劃的觀點看,字頻統計和字頻研究是任何國族不可缺少的一項基礎建設。好像攪國民經濟不能不先興建公路系統一樣,字頻統計之於文化教育,其重要性亦不遑多讓。一個國家建好了一套公路系統,如果沒有進一步的經濟活動讓其效益發揮,則建設便談不上意義。同樣地,字頻統計要變得有意義,要視乎我們能否於教育、語文、文化、社會、乃至政治、經濟和哲學等研究的場合裡善加利用。本網頁在製作過程中,有好幾位教育界人士曾對計劃的推行表示了很高的期待,這對我們來說,既是一種鼓勵,也是一份壓力。不過,在這個網頁完成的一天,我們感到如釋重負,因為從這一天開始,其餘的工作將可由廣大的用者分擔。
這個網頁的製作,涉及的主要是一些技術層面的工作。在重組資料的過程中,我們憑著新一代電算機快捷準確的便利,找到幾個原計劃中存在的小瑕疵(如一些造字的問題),但卻正因此而得以窺見,當年何教授和他的隊伍(包括幾位中文系畢業生)在研究策略的釐定和文字解讀的執行上實在投下了難以估量的心血,而這些心血大部份都不是機器智能 (machine intelligence) 所能取代的。因此,在總結這個網頁的時刻﹐我不能不對原計劃的全體同人再次致敬!
 使用凡例 - Users' Guide
使用凡例 - Users' Guide{kind=link}
 回到頁頂
| Top
回到頁頂
| Top  回到主頁
| Home
回到主頁
| Home